


Let's understand Cross-Validation! #7
Are you ready to run a race?

Imagine, you are preparing for a big race. You want to make sure that you are ready for different types of tracks you might encounter on the race day.
For training, you choose an area which is a combination of roughly five different surfaces: hills, dirt paths, gravel, grass and flat ground. You mark them as track1, track2, track3, track4 and track5 respectively.
Each day, you train on a different set of four tracks followed by testing your performance on the remaining track known as the test track. The performance metric is the time taken to complete the test track.
Let me simplify it further for you!
Suppose, on day 1, you practice on four tracks (track1, track2, track3, track4) and use track5 to test your performance. On day 2, you practice on different set of four tracks(track1, track2, track3 and track5) and use track4 to test your performance.
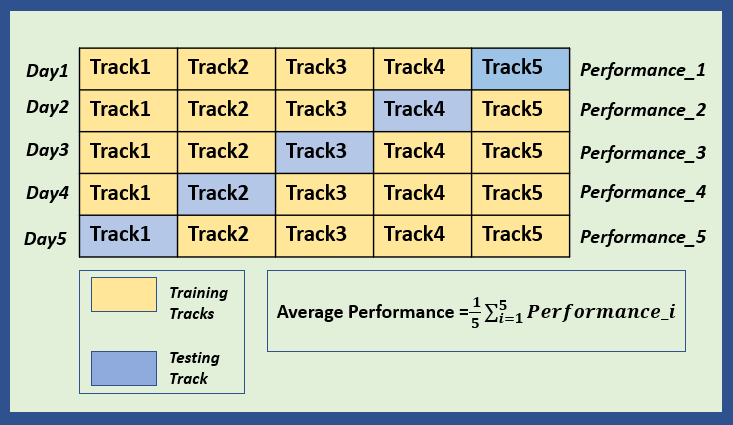
You repeat the same process until each track is used as a test track. At the end of five days, you will have the five time scores from five different test tracks. You average these five times scores to evaluate your overall running performance.
In addition to the time score, you introspect on other factors also. Did you maintain your pace? How did you feel during the run? What could you improve for the next session? This introspection will help you adjusting your training strategy to improve the overall running performance.
Cross-validation is like training on different tracks for the race. It involves splitting your dataset into multiple parts, training your model on some parts and then testing it on the remaining parts. By doing this with different splits, you get a better idea of your model’s performance. Just like running on different types of tracks gives you a better idea of your running capacity.
Below are the steps on how how cross-validation works. Let’s see how running practice translates into cross-validation in machine learning.
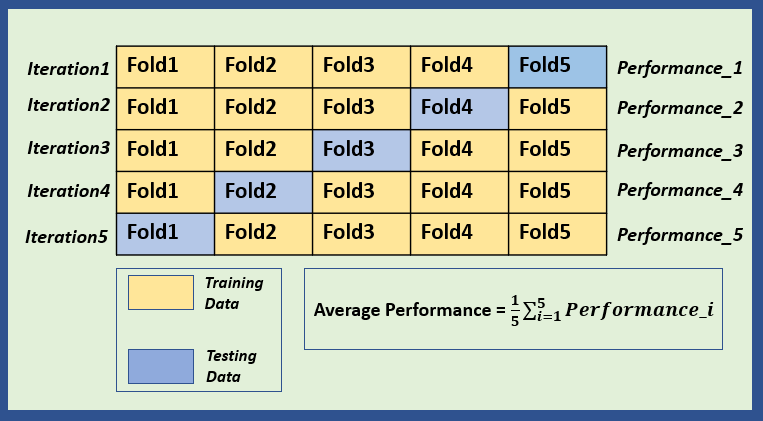
Splitting the data
The data is split into multiple parts known as folds. The number of these folds may vary.
This is similar to dividing your training area in different types of tracks.
Training and Testing
In each iteration, one fold is set aside as the test set and the remaining folds are used to train the model.
This is similar to training each day on a set of four tracks and evaluating the performance on the remaining track known as the test track.
Model Evaluation
The model’s performs is evaluated on each test set once the training is done.
This is similar to evaluating your running performance on the test track after each training session on the four tracks.
Repeat the process
The process of training and testing is repeated multiple times, with each fold being used as a test set once. If there are 5 folds. The process will be repeated 5 times.
This is similar to switching tracks for training and testing your running performance.
Calculate Average Performance
Once the model is trained and tested on each fold, the average performance will be calculated. If there are 5 folds, there will be 5 performance scores after all the rounds. These 5 scores are averaged to get a single performance score. This averaged performance score provides an overall estimate of model’s performance.
This is similar to getting the average of your running performance across all the 5 tracks to see how well you are prepared for the race.
Adjust the Model
Based on the cross-validation results, the model can be adjusted to perform better.
This is similar to adjusting the training strategy to improve your running performance.
So, the above discussion explains that cross-validation in machine learning is similar to preparing for a race.
Instead of focusing on just one training and testing scenario, you split your data into different parts (like different running tracks). By training and testing your model on each part, you get a more comprehensive understanding of how well your model is performing. Just as with your running practice, you want to see how your model does in different conditions, and then you average the results to gauge its overall performance.
So, just as training for a race prepares you for the race day, cross-validation helps you prepare your machine learning model for real-world performance!
Let me know if this analogy was helpful to you!
In the upcoming newsletters, we’ll discuss the following topics in detail:
-Different types of cross-validation techniques
-Different uses of cross-validation
-Comparison between train-test split and cross-validation
and much more!
Stay tuned for the same!
Curious about a specific AI/ML topic? Let me know in comments.
Also, please share your feedbacks and suggestions. That will help me keep going.
See you next Friday!
-Kavita
Quote of the day
"Success is no accident. It is hard work, perseverance, learning, studying, sacrifice and most of all, love of what you are doing or learning to do." — Pele
P.S. Let’s grow our tribe. Know someone who is curious to dive into ML and AI? Share this newsletter with them and invite them to be a part of this exciting learning journey.
Hyperparameter tuning and cross-validation:
We test the performance of different hyper-parameters using cross-validation.
Let's say, the hyper-parameter H1 had the highest average score in cross-validation.
Now, we will take H1 and then train a new model but this time we will use complete training data. No test and train testing is required this time as we have already proven the stability/performance of hyper-parameter H1 using cross validation.
This is how you will get to the final model, right?