


Exploring various cross-validation techniques! #8
Do you know about them?

Before we begin today, I need to make sure one thing.
Did you check the last week’s newsletter?
If not, I will suggest to check it once. The link is here:

That newsletter explained cross-validation with the help of a real-life example. You’ll find it interesting to see how the concept of cross-validation is similar to preparing for a race. Whether you are a beginner or already an experienced professional, this analogy will help you grasp this important machine learning concept better.
Read it and let me know if it was helpful to you. Based on your feedback, I will use more real life examples to explain difficult machine learning concepts in my upcoming newsletters.
Why learning about cross-validation is so important?
-It plays multiple roles such as evaluating a model's performance, selecting the best model, preventing overfitting, hyperparameter tuning etc.
-Due to its multiple uses, this topic is often asked in machine learning interviews. So, prepare it well.
Today, we’ll discuss about the most commonly used cross-validation techniques. These cross-validation techniques are different based on how the data is split for training and testing the model.
Holdout Method
This is the simplest cross-validation technique. The dataset is randomly split into two subsets: training set and test set. The model is trained on the training set and evaluated on the test set. Most commonly used split ratios between training and test sets are 70-30, 80-20 etc. The split ratio varies depending on the use case and sufficiency of the available data. Generally, the size of training set is larger than the test set.

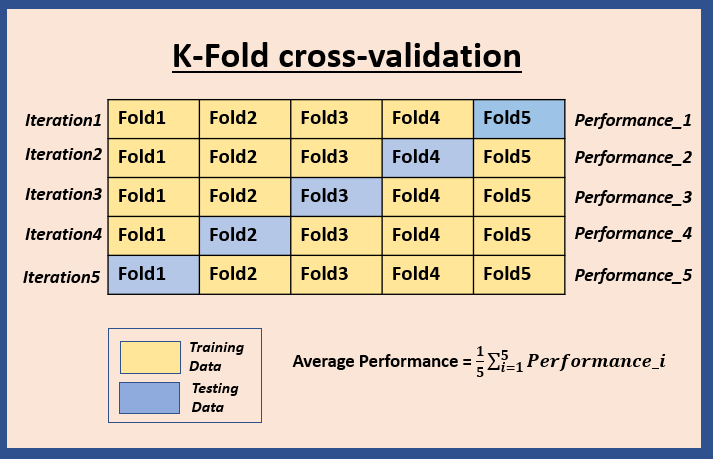
K-Fold cross-validation
The dataset is divided into K sets (known as folds) of almost equal size. One fold is kept aside as a test set and the model is trained on the remaining K-1 folds. This process is repeated K times until each fold serve as a test set once. This means, the model is trained K times, each time using different training and test data. The final performance metric is the average of performance scores obtained in each iteration. This tells about the model's predictive capability across the entire dataset.
In the example below, K=5 has been used for illustration purpose.
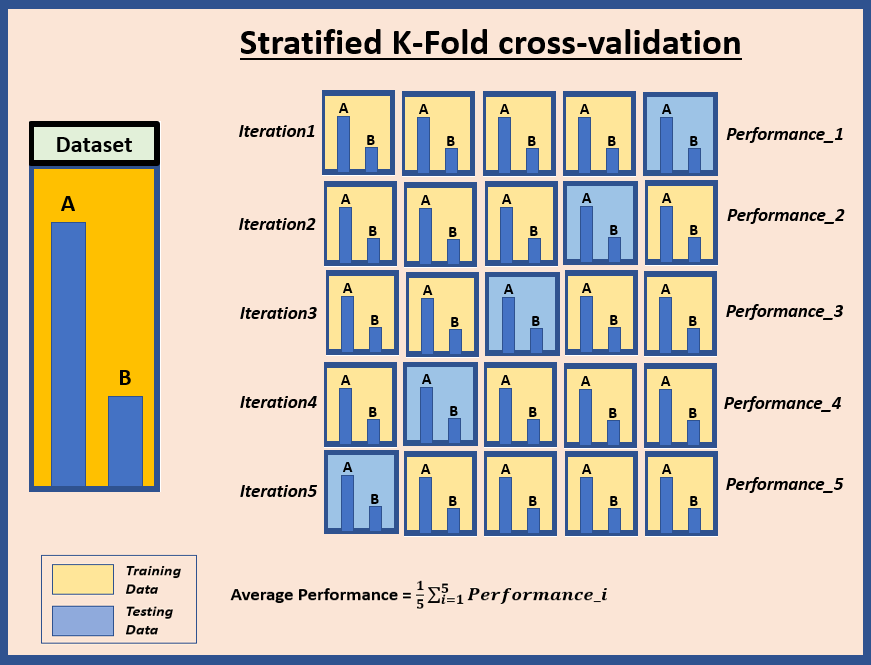
Stratified K-Fold cross-validation
This is a an advanced version of the K-fold cross-validation and is quite useful for imbalanced datasets. In K-fold cross-validation, the dataset is randomly divided into K folds. But in stratified K-fold cross-validation, the datasets is divided into K-folds in a way that each fold maintains the proportion of categories of target variable similar to the entire dataset. The final performance metric is the average of performance scores obtained in each iterations. This tells about the model's predictive capability across the entire dataset.
In the example below, K=5 has been used for illustration purpose.
Suppose, you have a dataset which contains 70% instances of class A and 30% instances of class B. So, the same proportion of 70% of A and 30% of B is maintained in each fold.
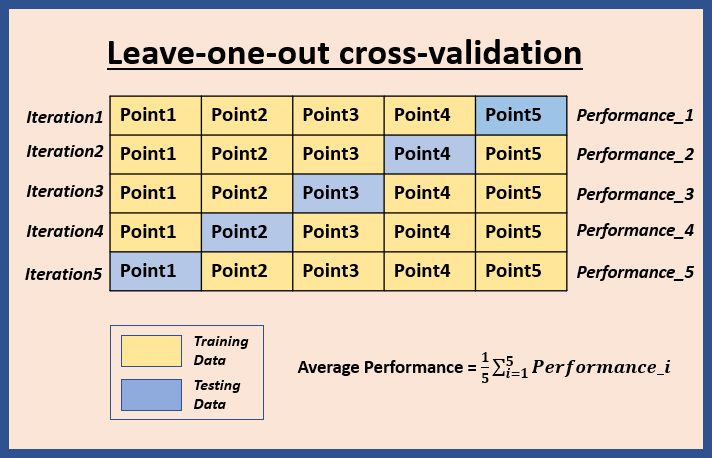
Leave-one-out cross-validation
Suppose, your dataset contains N points. Each data point in the dataset is used as test set once and the remaining N-1 data points are used for training. The process is repeated N times until each point in the dataset is used as a test set once. It means the model is trained N times. The final performance metric is the average of performance scores obtained in each iterations. This tells about the model's predictive capability across the entire dataset.
In the example below, N=5 has been used for illustration purpose.
Leave-P-out cross-validation
This is similar to Leave-one-out cross-validation. But instead on one data point out, P data points are left out for testing and remaining N-P are used for training. The process continues until all combinations of P data points are used for testing. The final performance metric is the average of performance scores obtained in each iteration. This tells about the model's predictive capability across the entire dataset.
In the example below, N=5 and P=2 have been used for illustration purpose.

Time series cross-validation
Time series cross-validation is different from other cross-validation techniques that split data randomly. Time series cross-validation is applied on the time series data. So, it is important to maintain the temporal order while splitting the data. Temporal order means maintaining the sequential structure of data during training and testing.
The time series dataset is divided into multiple subsets, typically by splitting it into contiguous blocks of data. Each subset represents a different time period, ensuring that observations from earlier time periods are used to predict observations from later time periods. The model is trained on historical data up to a certain point and then tested on the immediate future data. The process is repeated until all the subsets have been used for model evaluation. The final performance metric is the average of performance scores obtained in each iterations. This tells about the model's predictive capability across the entire time series.

Found it useful?
Curious about a specific AI/ML topic? Let me know in comments.
Also, please share your feedbacks and suggestions. That will help me keep going.
See you next Friday!
-Kavita
Quote of the day
"Learning is the beginning of wealth. Learning is the beginning of health. Learning is the beginning of spirituality. Searching and learning is where the miracle process all begins." - Jim Rohn
P.S. Let’s grow our tribe. Know someone who is curious to dive into ML and AI? Share this newsletter with them and invite them to be a part of this exciting learning journey.